
BY RYAN TULLY
September 30, 2024
Information security and data privacy have merged into a new single discipline called data protection. This article discusses why data discovery and classification is an essential element of a larger data protection program.
In Part 1 of this series, I reviewed the emergence in the U.S. of the discipline of data protection over the last half-century. In Part 2 I discuss the role of data discovery and classification in meeting the many data protection requirements that have been imposed by new laws and regulations.
Using Data Discovery and Classification to Meet Compliance Requirements
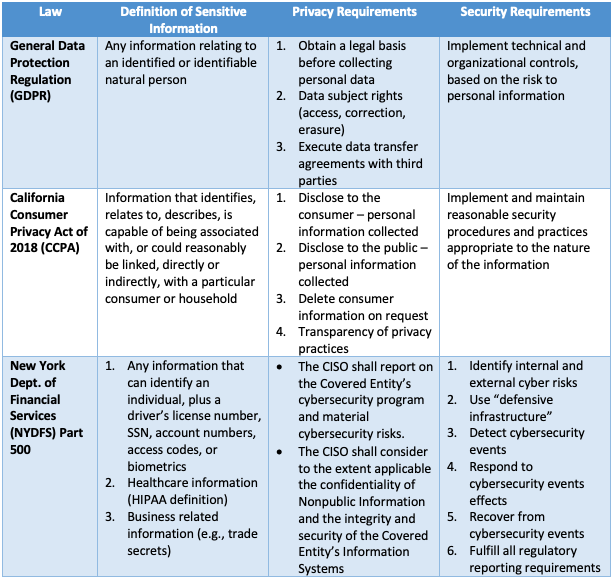
Nearly all modern data protection laws include privacy and security requirements, and typically include a specialized definition of sensitive information. Such information can take the form of personal data, trade secrets, or attorney-client privileged information. Some examples of these laws:
Key to complying with these requirements is:
- Discovering sensitive information and creating a data inventory; and
- Classifying that information according to the organization’s data protection standards.
Discovering sensitive information (data discovery) involves electronically searching an organization’s network and cloud stores (its information “ecosystem”). A data inventory is a system to track collection, use, storage, sharing, protection, and destruction of sensitive information. It represents a “single source of truth” as to the state of sensitive information from a legal and operational perspective.
Data classification looks at the data that courses through an information ecosystem and matches it with appropriate, risk-based controls. The process involves identifying documents or files containing sensitive information and embedding labels. Those labels are indicative of the controls that must be applied (Proprietary and Sensitive [C-3]) and regulations to which the data is subject (GDPR, CCPA, NYS Part 500). They can also address information governance mandates such as how long to keep the information before destroying it. Here’s an example of such labels embedded in the metadata of a document:
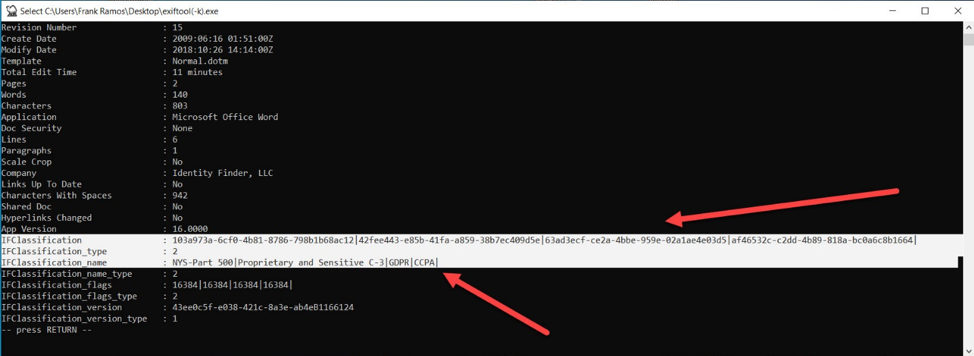
Data loss prevention (DLP) or next-general firewall (NGFW) systems read these embedded labels as information travels through the network. They then respond accordingly, based on built-in rules for determining what can’t be done with personal information (no uploads/downloads, no leaving the network, etc.). Those rules are driven by the laws or contracts that govern the organization’s use of sensitive information.
In part 3 of this series, I will describe how to develop a data classification system. I will also show how a larger data classification program will help you advance compliance with the many regulations and requirements your company likely faces.
See how Spirion can help you meet your compliance obligations with data protection. Download the CCPA whitepaper, How Spirion Advances Compliance with the California Consumer Privacy Act of 2018 (CCPA).